Check out this SlideShare Presentation:
Building Large jQuery Applications
View more presentations from Rebecca Murphey.
Check out this SlideShare Presentation:
Here are some FAQs about my tests.
The word "real" comes from www.hixie.ch/advocacy/testing-methodology where Ian Hickson explains in great details all possible combinations of tests. My tests focus on the "real world coverage", that is, some of the possible combinations of CSS features normally used for building a layout. Real tests fall usually in the category of "advanced tests" (W3C terminology). They are not minimal test cases, but they may be used to build these ones.
Yes, except the "Feel Like Lynx" demo, where I use -moz-binding in order
to stop the scrolling behaviour of the marquee element in Firefox.
This is a good example of user stylesheet.
That's probably due to the different screen resolution. Consider the fact that in some tests I use the Ahem font (www.hixie.ch/resources/fonts), so for a correct view you should install this font first.
Because IE (version 7 and lower) is affected by the hasLayout property. That means that IE has two different layout engines. hasLayout affects most of the CSS properties used in these tests (float, positioning, etc.). When IE drops its support to this property, it will be inserted in the browsers list.
I'm not interested in the campaigns pro/anti Microsoft's IE. What's more, I'm not interested in any kind of test that shows only the bugs of one browser.
That's true. But if you take a closer look at the site of Gerard Talbot (http://www.gtalbot.org/) you'll probably notice that also other browsers have al least one or more bugs. Take for example this test: http://www.css-zibaldone.com/test/css21/floats/advanced-layout-10/ If you point IE7 to that URI, you'll see an horizontal scrollbar that should not be there. The interesting point is that also Netscape 7.0 had the same problem with this kind of layout. Time passes, browser change and their CSS support improves. It's only a matter of time.
Maybe they are not "useful" from the "copy-and-paste" point of view, since they are all prototypes that should be adapted to your own needs. But, as I believe, you are an intelligent and skilled person who knows how to make them work also in other scenarios, so you won't have any kind of problem with these tests. For example, the first thing you could do is to remove the XML prologue in order to prevent IE6- from switching to quirks mode. Then you might always use the conditional comments for the debugging, giving IE its own code. Remember that almost all IE6-'s rendering bugs depend on having or not having layout. See http://www.satzansatz.de/cssd/onhavinglayout.html and http://www.positioniseverything.net/ for further details.
Perfectly aware. I'm not so conceited ^_^. I know also all my limits, mainly those concerning the lack of precision in using a scientific method. Anyway, I like to share my little knowledge with other people. That's all.
That's because IE7 (and lower) doesn't support any kind of XML-based MIME Type. I don't want to prevent IE's users from viewing my tests. It's a matter of accessibility.
Yes, but this is not intentional. I'm really concerned about accessibility problems. In fact, on my site I use only a color contrast approved by the Colour Contrast Analyzer of the W3C. As said before, my tests are only demos, and obviously I'll have to change my approach if I want to use them for some live projects. For example, in my image map I've used an ordered list to respect a progressive enumeration of the links. That's fine for screen readers and textual browsers. But using 'display: none' inside the list items is not so fine, so this is a thing that should be changed.
A browser should take the provided images as a reference. Obviously there could be some differences, mainly those concerning the user interface and the environment. For example, Safari has a different rendering of some form elements. That's not important. Anyway, a browser should *not* break the layout. That's important.
Mainly from real features that I've seen on the Web. For example, the "CSS Button" demo comes from an image found on the W3C site. The "Foo Fighters" demo comes instead from an LP cover of my CDs collection. Building such layouts is a challenge to me.
Yes. My starting screen resolution is 1024x768, so it's absolutely normal that a browser has to change its rendering when this or other factors are modified by the user. It doesn't mean that the test fails under such conditions.
I use a local validator to check if my pages are valid, since my site is static and I have to upload the new pages every time. However, there could be some discrepancies, especially between the declared encoding (UTF-8) and some characters used in the code. This is a trivial thing to fix. Simply, validate every page, note the errors occurred and fix them.
Recent thoughts of Steve Jobs on Flash:
Apple has a long relationship with Adobe. In fact, we met Adobe’s founders when they were in their proverbial garage. Apple was their first big customer, adopting their Postscript language for our new Laserwriter printer. Apple invested in Adobe and owned around 20% of the company for many years. The two companies worked closely together to pioneer desktop publishing and there were many good times. Since that golden era, the companies have grown apart. Apple went through its near death experience, and Adobe was drawn to the corporate market with their Acrobat products. Today the two companies still work together to serve their joint creative customers – Mac users buy around half of Adobe’s Creative Suite products – but beyond that there are few joint interests.
I wanted to jot down some of our thoughts on Adobe’s Flash products so that customers and critics may better understand why we do not allow Flash on iPhones, iPods and iPads. Adobe has characterized our decision as being primarily business driven – they say we want to protect our App Store – but in reality it is based on technology issues. Adobe claims that we are a closed system, and that Flash is open, but in fact the opposite is true. Let me explain.
First, there’s “Open”.
Adobe’s Flash products are 100% proprietary. They are only available from Adobe, and Adobe has sole authority as to their future enhancement, pricing, etc. While Adobe’s Flash products are widely available, this does not mean they are open, since they are controlled entirely by Adobe and available only from Adobe. By almost any definition, Flash is a closed system.
Apple has many proprietary products too. Though the operating system for the iPhone, iPod and iPad is proprietary, we strongly believe that all standards pertaining to the web should be open. Rather than use Flash, Apple has adopted HTML5, CSS and JavaScript – all open standards. Apple’s mobile devices all ship with high performance, low power implementations of these open standards. HTML5, the new web standard that has been adopted by Apple, Google and many others, lets web developers create advanced graphics, typography, animations and transitions without relying on third party browser plug-ins (like Flash). HTML5 is completely open and controlled by a standards committee, of which Apple is a member.
Apple even creates open standards for the web. For example, Apple began with a small open source project and created WebKit, a complete open-source HTML5 rendering engine that is the heart of the Safari web browser used in all our products. WebKit has been widely adopted. Google uses it for Android’s browser, Palm uses it, Nokia uses it, and RIM (Blackberry) has announced they will use it too. Almost every smartphone web browser other than Microsoft’s uses WebKit. By making its WebKit technology open, Apple has set the standard for mobile web browsers.
Second, there’s the “full web”.
Adobe has repeatedly said that Apple mobile devices cannot access “the full web” because 75% of video on the web is in Flash. What they don’t say is that almost all this video is also available in a more modern format, H.264, and viewable on iPhones, iPods and iPads. YouTube, with an estimated 40% of the web’s video, shines in an app bundled on all Apple mobile devices, with the iPad offering perhaps the best YouTube discovery and viewing experience ever. Add to this video from Vimeo, Netflix, Facebook, ABC, CBS, CNN, MSNBC, Fox News, ESPN, NPR, Time, The New York Times, The Wall Street Journal, Sports Illustrated, People, National Geographic, and many, many others. iPhone, iPod and iPad users aren’t missing much video.
Another Adobe claim is that Apple devices cannot play Flash games. This is true. Fortunately, there are over 50,000 games and entertainment titles on the App Store, and many of them are free. There are more games and entertainment titles available for iPhone, iPod and iPad than for any other platform in the world.
Third, there’s reliability, security and performance.
Symantec recently highlighted Flash for having one of the worst security records in 2009. We also know first hand that Flash is the number one reason Macs crash. We have been working with Adobe to fix these problems, but they have persisted for several years now. We don’t want to reduce the reliability and security of our iPhones, iPods and iPads by adding Flash.
In addition, Flash has not performed well on mobile devices. We have routinely asked Adobe to show us Flash performing well on a mobile device, any mobile device, for a few years now. We have never seen it. Adobe publicly said that Flash would ship on a smartphone in early 2009, then the second half of 2009, then the first half of 2010, and now they say the second half of 2010. We think it will eventually ship, but we’re glad we didn’t hold our breath. Who knows how it will perform?
Fourth, there’s battery life.
To achieve long battery life when playing video, mobile devices must decode the video in hardware; decoding it in software uses too much power. Many of the chips used in modern mobile devices contain a decoder called H.264 – an industry standard that is used in every Blu-ray DVD player and has been adopted by Apple, Google (YouTube), Vimeo, Netflix and many other companies.
Although Flash has recently added support for H.264, the video on almost all Flash websites currently requires an older generation decoder that is not implemented in mobile chips and must be run in software. The difference is striking: on an iPhone, for example, H.264 videos play for up to 10 hours, while videos decoded in software play for less than 5 hours before the battery is fully drained.
When websites re-encode their videos using H.264, they can offer them without using Flash at all. They play perfectly in browsers like Apple’s Safari and Google’s Chrome without any plugins whatsoever, and look great on iPhones, iPods and iPads.
Fifth, there’s Touch.
Flash was designed for PCs using mice, not for touch screens using fingers. For example, many Flash websites rely on “rollovers”, which pop up menus or other elements when the mouse arrow hovers over a specific spot. Apple’s revolutionary multi-touch interface doesn’t use a mouse, and there is no concept of a rollover. Most Flash websites will need to be rewritten to support touch-based devices. If developers need to rewrite their Flash websites, why not use modern technologies like HTML5, CSS and JavaScript?
Even if iPhones, iPods and iPads ran Flash, it would not solve the problem that most Flash websites need to be rewritten to support touch-based devices.
Sixth, the most important reason.
Besides the fact that Flash is closed and proprietary, has major technical drawbacks, and doesn’t support touch based devices, there is an even more important reason we do not allow Flash on iPhones, iPods and iPads. We have discussed the downsides of using Flash to play video and interactive content from websites, but Adobe also wants developers to adopt Flash to create apps that run on our mobile devices.
We know from painful experience that letting a third party layer of software come between the platform and the developer ultimately results in sub-standard apps and hinders the enhancement and progress of the platform. If developers grow dependent on third party development libraries and tools, they can only take advantage of platform enhancements if and when the third party chooses to adopt the new features. We cannot be at the mercy of a third party deciding if and when they will make our enhancements available to our developers.
This becomes even worse if the third party is supplying a cross platform development tool. The third party may not adopt enhancements from one platform unless they are available on all of their supported platforms. Hence developers only have access to the lowest common denominator set of features. Again, we cannot accept an outcome where developers are blocked from using our innovations and enhancements because they are not available on our competitor’s platforms.
Flash is a cross platform development tool. It is not Adobe’s goal to help developers write the best iPhone, iPod and iPad apps. It is their goal to help developers write cross platform apps. And Adobe has been painfully slow to adopt enhancements to Apple’s platforms. For example, although Mac OS X has been shipping for almost 10 years now, Adobe just adopted it fully (Cocoa) two weeks ago when they shipped CS5. Adobe was the last major third party developer to fully adopt Mac OS X.
Our motivation is simple – we want to provide the most advanced and innovative platform to our developers, and we want them to stand directly on the shoulders of this platform and create the best apps the world has ever seen. We want to continually enhance the platform so developers can create even more amazing, powerful, fun and useful applications. Everyone wins – we sell more devices because we have the best apps, developers reach a wider and wider audience and customer base, and users are continually delighted by the best and broadest selection of apps on any platform.
Conclusions.
Flash was created during the PC era – for PCs and mice. Flash is a successful business for Adobe, and we can understand why they want to push it beyond PCs. But the mobile era is about low power devices, touch interfaces and open web standards – all areas where Flash falls short.
The avalanche of media outlets offering their content for Apple’s mobile devices demonstrates that Flash is no longer necessary to watch video or consume any kind of web content. And the 200,000 apps on Apple’s App Store proves that Flash isn’t necessary for tens of thousands of developers to create graphically rich applications, including games.
New open standards created in the mobile era, such as HTML5, will win on mobile devices (and PCs too). Perhaps Adobe should focus more on creating great HTML5 tools for the future, and less on criticizing Apple for leaving the past behind.
Steve Jobs
April, 2010
Awesome talk by John Resig.
DOM can be actually expensive in terms of performance if not handled properly. Here are some tips and gotchas.
Stoyan Stefanov is one of the most skilled JavaScript developers at Yahoo.
Great talk by Molly Holzschlag.
Great slides by Russ Weakley.
Sometimes people ask me what's the point in creating a so huge collection of CSS tests. So here are some explanations. First of all, the tests I made are just the result of a good amount of spare time. Being unemployed for a long time forces you to do something with your time schedules. Usually I started wondering about some issues with CSS layouts, for example about floats, positioning and the like and then I used to create a test case that could show why something worked or not. These are basically how my first tests look like to a visitor stumbling for the first time on them. But then came the W3C CSS Test Suite, where I had to get rid of my bad coding habits and get used to code following certain rules.
These kind of CSS tests are rather cryptic, because you have to look at the meta information of the page to see how they should work. I think that these tests are not very useful for a casual reader. It's better to stick to complete layouts and demos to get an idea about how a certain combination of properties should work together. So you should make a choice: W3C testing style or your own testing style. Be aware, however, that your custom style should be self-explanatory or you'll probably end up with receiving mails from people saying "Man, I didn't understand how to do this and that.".
When you make a test, just simply ask yourself what you're going to demonstrate. If it's not clear in your mind what you're going to show to your visitors, it's more likely that you'll fail with your purpose. Second, be clear, Third, even with complex layouts, write a good explanation about how your page should look like and, if proper, provide some screenshots. Remember: if something is not clear to you, it's likely that even your readers will have problems with your tests. So theory first: read the CSS specifications, read tests made by other developers, read the most relevant tutorial on the topic of your choice and, finally, be creative. Further, be ready to update your tests when browser support changes or a new bug comes along. By doing so, your tests will be simply useful and your visitors will be happy.
Something that I've seen only incidentally. Interesting!
Interesting technical talk.
Check out this SlideShare Presentation:
An interesting article by Mark Pilgrim shows some of the most interesting features of HTML 5 form elements. For example, something that literally drove me mad is the following:
<input type="text" name="email" id="email" required="required" />
So you might write a JavaScript code like this:
$('input[required]').each(function() {
// perform some validation tasks
});
Cool!
A great technical talk by Dave Raggett.
Just a short snippet on this method:
function addDirectorySeparator() {
var li = document.getElementsByTagName('li');
var i;
for(i=0; i<li.length; i++) {
if(li[i].firstChild.nodeName == 'KBD') {
var separatorContent = '-';
var separator = document.createElement('span');
separator.className = 'dir-sep';
separator.appendChild(document.createTextNode(separatorContent));
var item = li[i]
var kbd = item.getElementsByTagName('kbd')[0];
if(navigator.userAgent.indexOf('MSIE') == -1) {
item.insertBefore(separator, kbd);
} else {
var itemHTML = item.innerHTML;
item.innerHTML = '<span class="dir-sep">-</span>' + itemHTML;
}
}
}
insertBefore() has the following syntax: parentElement.insertBefore(newElement, referenceElement). You need a reference element to properly add the new element within the parent node. Of course Internet Explorer has some problems with this method, so I cut it straight and I wrote a subroutine just for it.
 Wamboo is the web agency I'm currently working for. It has a strong background (more than 15 years of experience in the field) and a beautiful surrounding (in the middle of green fields). It's surely my best working experience with an agency. Here's the map of the area where Wamboo is located.
Wamboo is the web agency I'm currently working for. It has a strong background (more than 15 years of experience in the field) and a beautiful surrounding (in the middle of green fields). It's surely my best working experience with an agency. Here's the map of the area where Wamboo is located.
Check out this SlideShare Presentation:
Check out this SlideShare Presentation:
Check out this SlideShare Presentation:
Interesting video. That's a good introduction to the MVC model in PHP.
The type of attribute selector we're going to use is called exact match attribute selector and has the form
E[attribute="value"], where E is the element to match. We want to:
label element.Let's see how we can actually achieve this goal with attribute selectors.
form input[type="text"] {
width: 150px;
border: 1px solid #ccc;
}
form label[for="first-name"],
form label[for="last-name"],
form label[for="email"],
form label[for="subject"] {
width: 140px;
padding-right: 10px;
display: block;
}
form label[for="first-name"],
form label[for="last-name"] {
background: transparent url("../img/name.png") no-repeat 100% 100%;
}
form label[for="email"] {
background: transparent url("../img/email.png") no-repeat 100% 100%;
}
We've specified a right padding on label elements which is equal to the width of
the background images. By doing so, we avoid any possible overlapping of text and background images when
the user resizes the text.
However, in Internet Explorer 7 the background images won't be displayed at all, because this
browser doesn't allow this kind of styling on label elements. To avoid this problem,
simply wrap the label elements with other elements (such as spans) and assign
the styles of labels to them. Fortunately, this problem has been fixed in Internet Explorer 8.
Sometimes it's useful for the user to print the URLs of a web document. CSS provides an easy way to accomplish this task: CSS3 attribute selectors and generated content. Assume that we have a page with different types of URLs, say, relative and absolute. In our printed version we want to display only the absolute ones. After setting our style sheet for print, we could write the following:
a {
color: #000;
}
a[href^="http://"]:after {
content: " (" attr(href) ") ";
}
The result is shown in the picture below.

What we did so far is the following:
http:// in the href attribute).:after pseudo-element to insert the generated string after the main content of the matched
a element. Note, however, that we're using the CSS3 grammar, so the pseudo-element should be written using
the double-colon notation (::after instead of :after).content property to insert the generated string. More precisely, this property inserts:
href attribute (returned by the attr() function), followed byUnfortunately, Internet Explorer (versions prior to 8) doesn't support generated content, so we have to follow another approach by using JavaScript.
The first thing to bear in mind is that all the code we're going to write should be put inside a conditional comment, like this:
<head> <!--[if lt IE 8]> ... <![endif]--> </head>
Second, our JavaScript code should perform the following operations:
a element in the document.href attribute.href attribute contains the string http://, then
href attribute, plus the parentheses.a element.The code is the following:
function addURL () {
var a = document.getElementsByTagName("a");
for (var i=0; i < a.length; i++) {
var url = a[i].getAttribute("href");
if(url.indexOf("http://") != -1) {
var span = document.createElement("span");
var textURL = document.createTextNode(" (" + url + ") ");
span.appendChild(textURL);
a[i].appendChild(span);
}
}
}
If you use anchors or relative URLs on your page, it's better to add && indexOf("yoursite/") == -1 to the main
if clause of the script. This allows us to avoid problems in Internet Explorer 7 (and lower), because this browser considers relative paths and anchors as if they were written with the http:// prefix. Bear in mind that you have to change
the string yoursite/ in order to select the main directory of your web site.
Now there's a problem: the newly created span element will be visible outside the print preview. We need to add
a couple of style rules to solve the problem.
@media screen {
a span {display: none}
}
@media print {
a span {display: inline}
}
We've removed the span element from the screen by using display: none and then re-inserted it with
display: inline for print. You can see the result in the picture below.

Another interesting video on this topic.
The quality of this video is.. well, naive, (a rooster in background?), but the information provided here are useful. At least.
Another interesting video on Bugzilla.
This is a short but useful introduction to this smart bug tracking system.
Interesting conference.
An interesting video from O'Reilly.
A Google TechTalk that outlines the standard roadmap to develop extensions for Google Chrome.
Wikipedia reports the following variant of this filling text:
A common form of lorem ipsum text reads as follows:
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
Another version of the text uses word "adipisici" (rather than "adipisicing"). Other versions of lorem ipsum include additional words to add variety so that repeated verses will not word-wrap on the exact same phrases.
And here's how it might look like:

Since I attended classical study courses, I prefer to add also real Latin words to this dummy mix.
Interesting topic and interesting slides!
A good starting point into the vast world of XSLT.
Here's a screenshot that shows how Safari 4 passes the Acid Test 3.

Perhaps I'm reinventing the wheel, but still. I was wondering why Safari and Chrome fail to correctly insert a string with the last modification date at the bottom of my pages. As usual, I've set up a test to check out what's wrong.
Surprisingly, both Chrome and Safari support the lastModified property of the document object only when the page is on a web server. However, they still fail to insert a date created as a timestamp from lastModified. I think this is somewhat related with a couple of problems that affected older versions of Webkit, mainly due to some obscure details of the implementation of the Date object (Safari 3 returned NaN, for example).
So they don't display the timestamp and I think that I'll have to make some further tests to fix this problem. Stay tuned!
Interesting and stimulating video.
Though this guy doesn't use a very performing editor, this video is actually interesting.
Check out this SlideShare Presentation of Marco Olivetti, a talented Italian web designer:
Check out this SlideShare Presentation:
Check out this SlideShare Presentation:
Check out this SlideShare Presentation:
Check out this SlideShare Presentation:
 One of the most famous Wordpress plugins concerning SEO.
One of the most famous Wordpress plugins concerning SEO.
A great video from Nicholas C. Zakas of Yahoo!, speaking at a Google Tech Talk.
An interesting video on the most famous versioning system.
Interesting video on one of the most useful aspects of the Zend Framework.
In the last hours many Gmail accounts have been compromised (including mine) and used to send spam. I had to reconfigure my account after recovering it. Too bad. Even my Blogger account was affected and blocked by Google to prevent attackers from inserting malicious code. Too bad. I'll probably have to switch to another mail account, less known but more secure.
Check out this SlideShare Presentation:
A really interesting topic in algorithms for parsing.
![]()
Here's a little excerpt taken from the nsCSSScanner.cpp library of the
Firefox source code. Notice of the CSS lexical table is build token by token.
void
nsCSSScanner::BuildLexTable()
{
gLexTableSetup = PR_TRUE;
PRUint8* lt = gLexTable;
int i;
lt[CSS_ESCAPE] = START_IDENT;
lt['-'] |= IS_IDENT;
lt['_'] |= IS_IDENT | START_IDENT;
lt[' '] |= IS_WHITESPACE; // space
lt['\t'] |= IS_WHITESPACE; // horizontal tab
lt['\r'] |= IS_WHITESPACE; // carriage return
lt['\n'] |= IS_WHITESPACE; // line feed
lt['\f'] |= IS_WHITESPACE; // form feed
for (i = 161; i <= 255; i++) {
lt[i] |= IS_IDENT | START_IDENT;
}
for (i = '0'; i <= '9'; i++) {
lt[i] |= IS_DIGIT | IS_HEX_DIGIT | IS_IDENT;
}
for (i = 'A'; i <= 'Z'; i++) {
if ((i >= 'A') && (i <= 'F')) {
lt[i] |= IS_HEX_DIGIT;
lt[i+32] |= IS_HEX_DIGIT;
}
lt[i] |= IS_IDENT | START_IDENT;
lt[i+32] |= IS_IDENT | START_IDENT;
}
}
Here's a generic wrapper that I use often while developing a new site:
function Site() {
var title = document.title;
var url = location.href;
var host = location.host;
var ua = navigator.userAgent;
var uaVer = parseFloat(navigator.appVersion);
this.getBrowser = function() {
var browser;
if(/Firefox/.test(ua)) {
browser = 'firefox';
} else if(/MSIE/.test(ua)) {
browser = 'ie';
} else if(/Opera/.test(ua)) {
browser = 'opera';
} else if(/\d\.\d\sSafari/.test(ua)) {
browser = 'safari';
} else if(/Chrome/.test(ua)) {
browser = 'chrome';
} else {
browser = 'unknown';
}
return browser;
};
this.getIEVersion = function() {
var browser = this.getBrowser();
if(browser == 'ie') {
if(ua.indexOf('MSIE 7') != -1) {
return (browser + '7');
} else if(ua.indexOf('MSIE 8') != -1) {
return (browser + '8');
} else {
return (browser + '6');
}
} else {
return;
}
};
}
Obviously you can add more generic methods and properties to this wrapper. Notice, however, how the first variables act more like constants than variables (the keyword const is not widely supported) and are available only inside the object that hosts them (in fact, they quite resemble the behavior of private members).
I stumbled on this review of the most popular JavaScript syntax highlighters. They seem all interesting to me, but the key question is: are they important? The fact that they only present the source code in a good-looking fashion doesn't necessarily mean that this is a feature that a web developer should consider a must for his/her site.
It's vital to notice that an important aspect of the topic has been overlooked: how to add semantics to the elements that will contain our source code? JavaScript highlighters don't add semantics but they only transform a raw sequence of lines into something structured. What about microformats? That would be a semantic feature that could actually improve the quality of our documents. For example:
<span rel="variable">var foo;</span>
This is only one possible application of microformats from the point of view of the semantics of our code. Of course we could also use the too often neglected code and samp elements to provide an extra layer of semantics.
SEO stands for Search Engine Optimization and defines a whole set of techniques and best practices to adopt in order to get a better indexing on search engines (e.g. on Google, which is the most important one). The basic concept of SEO is incredibly simple to understand: content first (CF). This means that we should write our markup by putting the relevant content before the rest of the document. Take for example the following markup:
<body><div id="site"><div id="header"><div id="branding"><h1>Site title</h1><p id="description">Site description</p></div><form action="#" method="get">
</form><div id="navigation"><ul></ul></div></div></div></body>In this example, the branding section contains the relevant content and so it comes
first in the source. Nothing special so far. But what if we decide to display the navigation menu
before the main header? We cannot modify the original source code, because by doing so we'll put the
navigation element before the remaining content. We could use a CSS solution by using positioning, but this would require a lot of code to make
sure that the elements will not overlap when the user decides to resize the text. That's why we need
the power of jQuery to accomplish this task, as explained in the next section.
The jQuery's motto is Do more with less. This is particularly true if we take a look at the code required to accomplish our task, which is as follows:
$(document).ready(function() {
var $navigationCopy = $('#navigation').clone();
$('#navigation').remove();
$navigationCopy.insertBefore('#header');
});
Do more with less: only 5 lines of code needed! First, we make a copy of our navigation menu
by using the clone() method, then we remove the original navigation menu from the
DOM with the remove() method, and finally
we insert our copy before the header element through insertBefore().
Using only CSS would require more code and a painful testing to check if our styles work correctly across browsers. Instead, using jQuery leaves our styles untouched and, what's more, perfectly cross-browser.
Note This post is the natural completion of a previous post about jQuery and containing floats.
I've set up a sample page where you can see the
float property in action. The list that contains the floated elements has been deliberately left
without any clearing class applied to it. Now it's time to fix it using jQuery. Why jQuery? Because we don't
want to manually add a class to the list, that's all.
The jQuery code required here is very short, as usual:
$(document).ready(function() {
$('*').each(function() {
$that = $(this);
if($that.css('float') !== 'none') {
$that.parent().addClass('clearfix');
}
});
});
The above code loops through all the elements of the page and when it encounters an element that has the float property
set to a value different from none, it applies the clearfix class to its parent. Do more with less!
Here's an interesting video that shows you how to start coding with the MVC model using the Zend Framework.
A couple of minutes ago I performed a massive Google search looking for information about the official sites of various Italian Ferrari clubs. Most of these sites (well, practically all) don't use RSS/Atom feeds, so it's almost impossible to try to aggregate them using their feeds. So I'll have to try another way. The point is that I basically need a common series of APIs to allow site developers to send their material through a common interface. PHP offers an excellent support to SOAP, so I think that this would be one of the feasible options. Using XML and Ajax would be nice too. The problem here lies in the definition of a common API used to send/receive data through the web. What I'm going to do in the next months is basically trying to develop such an API. Wish me good luck!
Here's a small excerpt from a class that I've developed recently.
class Common
{
public function createRandomString($length = 8)
{
$string = '';
$possible = '0123456789bcdfghjkmnpqrstvwxyz';
$i = 0;
while($i < $length) {
$char = substr($possible, mt_rand(0, strlen($possible)-1), 1);
if (!strstr($password, $char)) {
$string .= $char;
$i++;
}
}
return $string;
}
public function filterEmail($email)
{
$filtered = str_replace('@', '@', $email);
$filtered = str_replace('.', '.', $filtered);
return $filtered;
}
public function mySQLDateToItalianFormat($date)
{
// MwSQL 'date' : yyyy-mm-dd
$day;
$month;
$year;
$formatted_date;
$date_parts = explode('-', $date);
switch($date_parts[2]) {
case '01':
$day = '1';
break;
case '02':
$day = '2';
break;
case '03':
$day = '3';
break;
case '04':
$day = '4';
break;
case '05':
$day = '5';
break;
case '06':
$day = '6';
break;
case '07':
$day = '7';
break;
case '08':
$day = '8';
break;
case '09':
$day = '9';
break;
default:
$day = $date_parts[2];
break;
}
switch($date_parts[1]) {
case '01':
$month = 'gennaio';
break;
case '02':
$month = 'febbraio';
break;
case '03':
$month = 'marzo';
break;
case '04':
$month = 'aprile';
break;
case '05':
$month = 'maggio';
break;
case '06':
$month = 'giugno';
break;
case '07':
$month = 'luglio';
break;
case '08':
$month = 'agosto';
break;
case '09':
$month = 'settembre';
break;
case '10':
$month = 'ottobre';
break;
case '11':
$month = 'novembre';
break;
case '12':
$month = 'dicembre';
break;
default:
break;
}
$year = $date_parts[0];
$formatted_date = $day . ' ' . $month . ' ' . $year;
return $formatted_date;
}
public function mySQLDateTimeToItalianFormat($datetime) {
// datetime format : yyyy-mm-dd hh:mm:ss
$formatted_datetime;
$date_parts = explode(' ', $datetime);
$date = $date_parts[0];
$formatted_date = $this->mySQLDateToItalianFormat($date);
$time = $date_parts[1];
$formatted_datetime = $formatted_date . ' ' . $time;
return $formatted_datetime;
}
public function markupURLs($text) {
$url_re = '#\b((https?|ftp|file)://|(www|ftp)\.)[-A-Z0-9+&@\#/%?=~_|$!:,.;]*[a-z0-9+&@\#/%=~_|$]#i';
if(preg_match($url_re, $text)) {
$text = preg_replace($url_re, '<a href="$0">$0</a>', $text);
}
return $text;
}
}
In this post, I'll explain some basic techniques for reading and writing styles by using jQuery.
jQuery provides the css() method for reading and writing styles. This method can be attached to every single
element on the page. The features of this method are explained below.
The css() method can be used to retrieve a style property of the first matched element. Shorthand properties are
not supported. For example, if you want to retrieve the rendered top margin, you should write marginTop instead of
margin-top. Example:
$(document).ready(function() {
var marginTop = $('#test').css('marginTop');
$('<p></p>').html('The margin-top value of the preceding element is ' + '<strong>' + marginTop + '</strong>.').insertAfter('#test');
});
Another feature of the css() method is the ability of writing a single style rule on the
first matched element. In this case, you should put the property name and its value inside quotes and
separate them with a comma. For example:
$(document).ready(function() {
$('#test').css('background', 'lime');
});
The css() method accepts as its argument a JavaScript object literal where you can write
multiple style rules. The syntax is: {'property1': 'value1', 'property2': 'value2', 'propertyn': 'valuen'}. You can also assign your object literal to a variable and then pass it to the
css() method. By doing so, your code remains clean and you don't have to write multiple
style rules on a single line. Further, your code will be faster because the object literal will be loaded first by the browser. Example:
$(document).ready(function() {
var cssStyles = {
'background': 'lime',
'padding': '0.5em',
'margin': '1em 0',
'border': 'thin solid green'
};
$('#test').css(cssStyles);
});

Just seen on Amazon:
If you're like most developers, you rely heavily on JavaScript to build interactive and quick-responding web applications. The problem is that all of those lines of JavaScript code can slow down your apps. This book reveals techniques and strategies to help you eliminate performance bottlenecks during development. You'll learn how to improve execution time, downloading, interaction with the DOM, page life cycle, and more.
Yahoo! frontend engineer Nicholas C. Zakas and five other JavaScript experts -- Ross Harmes, Julien Lecomte, Steven Levithan, Stoyan Stefanov, and Matt Sweeney -- demonstrate optimal ways to load code onto a page, and offer programming tips to help your JavaScript run as efficiently and quickly as possible. You'll learn the best practices to build and deploy your files to a production environment, and tools that can help you find problems once your site goes live.
- Identify problem code and use faster alternatives to accomplish the same task
- Improve scripts by learning how JavaScript stores and accesses data
- Implement JavaScript code so that it doesn't slow down interaction with the DOM
- Use optimization techniques to improve runtime performance
- Learn ways to ensure the UI is responsive at all times
- Achieve faster client-server communication
- Use a build system to minify files, and HTTP compression to deliver them to the browser
In other words, next book to buy.
Interesting video, with some good insights.
Amazon is a good example of a company web site that offers alternate contents to handle the special needs of people who use assistive technologies. For example, if you open the site's main page with Lynx (the textual browser), you will see an informative notice like this:
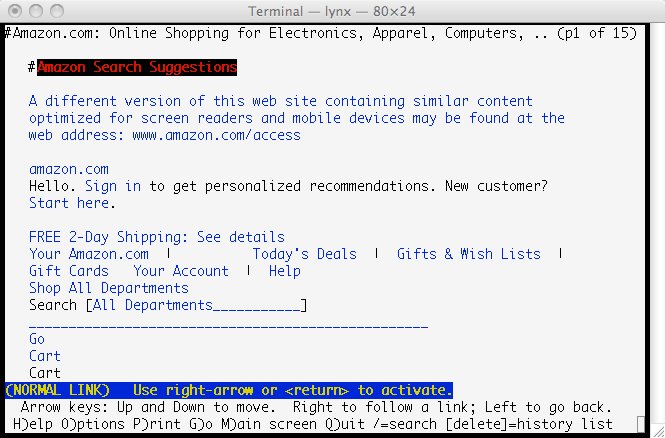
This notice notifies the user that an accessible version of the web site is available at www.amazon.com/access. On Lynx, you have just to type g followed by the address and then press Enter. You will see the following:

As you can see, this page is completely different from the former, though its contents are basically the same. Again, Amazon offers a really effective way of handling users with particular needs.
A little bit old but still interesting video.
 My little niece Matilde now has her own public page on Facebook! You can join this page as a fan. Hail, hail Matilde!
My little niece Matilde now has her own public page on Facebook! You can join this page as a fan. Hail, hail Matilde!
I must confess that I love to embrace every new CSS technique that comes on my way. But when it comes to CSS sprites, I have to say that it was quite disappointing to find out that this technique poses more problems than it solves. The first problem concerns the vertical offset of the y-axis of the background image positioning. Since sprites are different, we have to deal with new calculations for every new image. Generally, sprites are splitted into rows. Each row has a different height depending on the height of the image contained inside that very row. What's more, there's also a vertical gap between rows that must to be taken into account. So calculations vary from sprite to sprite and there's no universal ratio that allows us to perform this task quite automatically. If things can be simple for a 120 x 100 pixels sprite, where each row is 20 pixels high, things get more complicated when you have to deal with sprites having odd measures.
What happens if we have to change sprites? New calculations have to be made, and this implies more time spent with those calculations. It's true that CSS sprites reduce the loading of a web page, but it's also true that this benefit is surely relevant only on sites with an heavy burden of assets to be displayed or with a lot of traffic. On medium or small web sites, this effect is almost irrelevant. So I don't think that CSS sprites are the new holy grail for saving bandwidth or decrease loading times. The truth, on the contrary, lies elsewhere, for example in a correct server configuration, in a proper resource compression and, finally, in a fast web server. Remember: it's always a matter of hardware, not software.
One day I'll buy it! I promise. I'm too eager to see how it works. In the meantime, I watch videos and sigh.
This video doesn't answer a basic question: how to make sure that users won't be able to submit multiple choices but just a single one? Again, I'll have to check it out by myself.
Ajax form validation should be handled with extreme care. I'm not a big fan of client-side validation because of the fact that it's unreliable. However, this video is interesting.
Interesting but well-known. I mean, what's the point in avoiding page refresh? It just takes a few instants. Am I missing something? Or maybe I'm just too retro...
Input files are considered by many web developers one of the most difficult topic to deal with using CSS. The basic problem with input files (form fields like input[type="file"]) lies in the fact that this kind of form fields has to do with sensitive information sent from clients to servers. In that vein, browsers tend to treat them very carefully. There are some gotchas to remember.
First, you cannot hide them with display: none or visibility: hidden without removing them entirely from the document. Browsers don't allow this technique. I've also tried a different approach using negative indentation and negative positioning by replacing the input field with an image. It works in some browsers, but not in all. Some browsers remove the element completely, so that you cannot select a file by clicking on the background image. The fact is that not all browsers consider the field active. In other words, if you click on the field without clicking on the "Browse" button, Firefox will prompt you a window to browse your filesystem, but not Internet Explorer. Further, things get more complicated in Safari, which has its own way to treat this kind of fields.
Second, most of the techniques proposed on the web work only on certain browsers but not on all. For example, an
interesting technique proposed by Shaun Inman (very interesting indeed) makes use of CSS and JavaScript to replace a file input field with an image. This technique sets the opacity of the element to 0, so that it can be replaced by a background image. It works well on IE, Firefox and Safari, but it fails completely on Opera, because this browser, at the time of this writing, doesn't support the CSS properties related to opacity. I've also tried to find some information on a possible Opera extension called -o-opacity, but probably it doesn't even exist or it's not supported (or it has a different name).
Finally, always remember that browser default styles often take precedence over your styles. This is the case of Firefox, for example (you can check it out by opening the html.css and forms.css in your Firefox installation directory). Even worse, when browsers don't use their default stylesheet, they tend to use their own internal algorithms to handle this type of form elements. So be careful.
Interesting, especially for beginners. I'd like to spend more time with Wordpress. It's fascinating.
Producing markup is one of the main tasks that PHP must perform. However, this is sometimes a tedious task that forces us to embed our PHP code in the markup itself, which is not a good programming practice. We can ease the difficulty of this task with an object-oriented approach. Basically, widgets are small objects that can be used in various contexts. In our case, we need to create small chunks of code for XHTML elements. Here's an example:
class XHTML_Widget
{
protected $_type;
public function __construct($type)
{
$this->_type = $type;
}
public function drawWidget($attributes = '', $content = '')
{
return '<' . $this->_type . ' ' . $attributes . '>' . $content . '</' . $this->_type . '>';
}
}
Then the class can be used as follows:
require_once('XHTML_Widget.php');
$link = new XHTML_Widget('a');
echo $link->drawWidget('href="#"', 'Click me');
Note, however, that this class could be declared as abstract (and also its methods), for a better use of the encapsulation process.
The inventor of C++.. what else should I say? The man who took me six years ago from the shadows of a dull and meaningless life with no goals and make me discover the beauty of the IT world and my skills... though sometimes when I code badly I still have some doubts about it. :-)
Anne Van Kesteren is one of the main figures behind the Opera browser. He's the author of the official XMLHttpRequest specification plus some other standards that now I honestly don't remember.
In this interview, the creator of C++ speaks about this great language with some interesting insights.
Yes, installation comes first, but as web developers sometimes we need to know how to customize the basic appearance of our web applications.
Textpattern is probably my favorite CMS, though I'm recently switching to Drupal for job reasons.
Interview with the founder of Wordpress.
I was wondering about the possibility of using a global CSS reset file on my projects and eventually I decided to not use it. Why? Just because resetting all default styles used by a web browser is not always a good idea. Let's try to explain. We have a global reset like this:
html, body, h1, h2, h3, h4, h5, h6, ul, ol, p {
margin: 0;
padding: 0;
}
This seems a good idea for elements such as body or headings, but what about paragraphs? Usually paragraphs must have some white-space that divides them from the rest of the content. If you reset them from start, you'll end up with redefining them somewhere else in your stylesheet, and so you're actually going to specify more than one single style rule. And that means duplicating your code over and over again.
I'm just saying that you should always use reset files with extreme care and not just simply copy and paste on your own site. In other words, what is useful for the author of the reset CSS file may not be good for you. Take care then.
A great video from Alex Martelli, one of the authors of Python Cookbook.
Interesting video from Google. If you're into Ajax and JavaScript, this is for you.
Planning something is sometimes much harder than doing it. I'm currently testing a local web application, and I have to say that I'm doing this work without a proper planning. I mean, the application is still growing under my eyes but I didn't plan how to make it work. I didn't plan how to manage users, I didn't plan how to manage contents, so that my PHP classes are huge and full of redundant methods. The application, however, works well but it's clunky. This is not the way it was supposed to be.
So, planning. It's everything. Without planning, you may probably end up with thousand lines of code that basically do two or three tasks. Too bad. So you have to plan everything. First, is your application content-centric or user-centric (or a mix of the two)? Second, what can users do (registered or unregistered)? Third, how to manage contents? Should you use SEO-friendly URLs or not? What's the goal of your application? What does your client want? And your users?
To accomplish this task, you don't have to write code. Either you choose UML or a notebook or whatever you want, be aware of the fact that every detail defined here means some hundreds lines of code spared later. Believe me, I've been there. Just remember to take your time. No need to hurry in this phase of the development. Check everything and never forget to get a clear idea of the finished work.
And remember: take your time.