![]() Ajax responses are usually very simple to handle. Generally speaking, all you have to do is inserting the content of the response into the DOM. But sometimes they can be quite complex. Suppose that you have to perform a form validation with Ajax. The served-side language can either return a list of validation errors or a message indicating that the user has sent the form successfully. How can you choose between these two types of messages?
Ajax responses are usually very simple to handle. Generally speaking, all you have to do is inserting the content of the response into the DOM. But sometimes they can be quite complex. Suppose that you have to perform a form validation with Ajax. The served-side language can either return a list of validation errors or a message indicating that the user has sent the form successfully. How can you choose between these two types of messages?
I found a simple solution: for validation errors, I wrap the message inside the following HTML element.
<div class="error" rel="label"></div>
As you can see, I use the CSS class error as an internal flag. Instead, the rel attribute has a value that corresponds to the ID of the form field that needs to be highlighted. In my particular case, I've chosen to highlight its corresponding label element instead. On the contrary, the wrapper for successful responses is much simpler:
<div class="success"></div>
However, there's a catch: I usually serve my responses as text/plain, since they're considerably faster to load. What I really need is a function that parses error messages and another that inserts the message into the DOM. Here they are:
var parseValidationErrors = function(html) {
var errorList = $('<div class="error-list"></div>');
errorList.appendTo('#main');
errorList.html(html);
var lines = html.split('\n');
var attributes = [];
for(var i=0; i<lines.length; i++) {
var line = lines[i];
var attrRe = /rel=".+"/;
if(attrRe.test(line)) {
var match = line.match(attrRe);
var rawAttr = match[0];
var attr = rawAttr.replace('rel="', '').replace('"', '');
attributes.push(attr);
}
}
for(var j=0; j<attributes.length; j++) {
var rel = attributes[j];
var id = '#' + rel;
$(id).prev().addClass('error-label');
}
};
var parseSuccessMessage = function(target, html) {
$(target).replaceWith(html);
};
parseValidationErrors() uses regular expressions to find and extract the value of the rel attribute from the Ajax response, whereas parseSuccessMessage() simply replace an existing portion of the DOM with the Ajax content. Now we need a third function that is actually able to detect the type of message returned and act accordingly:
var detectResponseType = function(html) {
var errorClass = /class="error"/;
if(errorClass.test(html)) {
return false;
} else {
return true;
}
};
This function only tests whether the message returned contains the CSS class error. Now we can put it all together:
$('#testForm').submit(function(e) {
var data = 'test=foo&bar=baz';
$.ajax({
type: 'POST',
url: 'ajax.php',
data: data,
success: function(html) {
if(detectResponseType(html)) {
parseSuccessMessage('#test', html);
} else {
parseValidationErrors(html);
}
}
});
e.preventDefault();
});
 Although I eventually switched to jQuery almost a year ago, I've been using also Prototype for a very long time. During this period, I noticed some differences between jQuery and Prototype that I'd like to share here. First, Prototype is a JavaScript framework, whereas jQuery is actually a JavaScript library. A framework is something more related to a certain level of abstraction and actually more suitable for very complex applications than a library. On the other hand, a library is certainly a tool that turns out to be very useful for practical scenarios, such as leveling the differences between browser implementations, adding effects, handling events and so on.
Although I eventually switched to jQuery almost a year ago, I've been using also Prototype for a very long time. During this period, I noticed some differences between jQuery and Prototype that I'd like to share here. First, Prototype is a JavaScript framework, whereas jQuery is actually a JavaScript library. A framework is something more related to a certain level of abstraction and actually more suitable for very complex applications than a library. On the other hand, a library is certainly a tool that turns out to be very useful for practical scenarios, such as leveling the differences between browser implementations, adding effects, handling events and so on. Occasionally we will want to present our Excel spreadsheet data in a web page and find the options lacking. If you have ever exported a Microsoft Office document you will know the garbage formatting instructions that get sent along with the information. How can we preserve the Excel look without the Office markup? You are in luck, we have a solution!
Occasionally we will want to present our Excel spreadsheet data in a web page and find the options lacking. If you have ever exported a Microsoft Office document you will know the garbage formatting instructions that get sent along with the information. How can we preserve the Excel look without the Office markup? You are in luck, we have a solution!
 After several years of web development, plus two years of C++ programming, I have to confess that I do not understand why web developers sometimes blame browser implementors. In many web tutorials is repeated the expression "it's not rocket science" to denote something that's easy to understand and use effectively. Well, implementing a web browser is something very similar to rocket science, in the sense that we're talking about extreme complexity here, not some fancy effects that you can achieve with some jQuery's plugin.
After several years of web development, plus two years of C++ programming, I have to confess that I do not understand why web developers sometimes blame browser implementors. In many web tutorials is repeated the expression "it's not rocket science" to denote something that's easy to understand and use effectively. Well, implementing a web browser is something very similar to rocket science, in the sense that we're talking about extreme complexity here, not some fancy effects that you can achieve with some jQuery's plugin.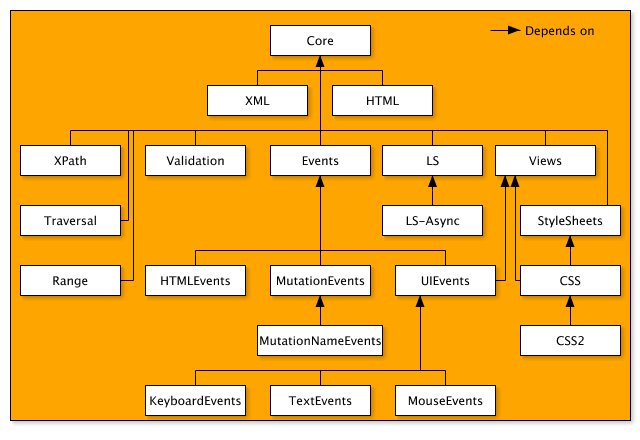

 The
The 
 I'm working on a MySQL database where all tables are encoded in UTF-8. One of the most required tasks on this database is creating downloadable CSV files to be read on Microsoft Excel. Creating a CSV file from a database is almost trivial, thanks to the PHP's
I'm working on a MySQL database where all tables are encoded in UTF-8. One of the most required tasks on this database is creating downloadable CSV files to be read on Microsoft Excel. Creating a CSV file from a database is almost trivial, thanks to the PHP's  XML namespaces were originally designed to avoid confusion between elements sharing the same characteristics. However, namespace should be created very carefully in order to avoid any possible collision. The first thing you need to bear in mind is that namespaces must have an higher degree of specificity than generic or public namespaces. For example, this is a perfectly valid XML namespace:
XML namespaces were originally designed to avoid confusion between elements sharing the same characteristics. However, namespace should be created very carefully in order to avoid any possible collision. The first thing you need to bear in mind is that namespaces must have an higher degree of specificity than generic or public namespaces. For example, this is a perfectly valid XML namespace: I noticed that many developers who start coding in CSS sometimes get confused by descendant and child selectors. In a nutshell: descendant selectors select an element that is contained within another element, disregarding its position in the DOM tree. On the contrary, child selectors select an element only when it's the direct child of its parent. For example, given the following structure:
I noticed that many developers who start coding in CSS sometimes get confused by descendant and child selectors. In a nutshell: descendant selectors select an element that is contained within another element, disregarding its position in the DOM tree. On the contrary, child selectors select an element only when it's the direct child of its parent. For example, given the following structure: JSON is gaining its momentum. Many websites have started using this format as their default format of choice for data exchange. One of the main reasons behind this choice is that JSON is a simple and lightweight format. RSS, on the other hand, is basically XML, implying that this format is more suitable when you have to deal with complex data structures, since XML is particularly useful for adding semantics to describe data (think about RDF, for example).
JSON is gaining its momentum. Many websites have started using this format as their default format of choice for data exchange. One of the main reasons behind this choice is that JSON is a simple and lightweight format. RSS, on the other hand, is basically XML, implying that this format is more suitable when you have to deal with complex data structures, since XML is particularly useful for adding semantics to describe data (think about RDF, for example). CSS classes can actually be combined together on the same element to get interesting results due to the cascade. As I said in an
CSS classes can actually be combined together on the same element to get interesting results due to the cascade. As I said in an 
 Almost a year ago I made some tests with CSS and emails for a personal project involving the creation of HTML templates to be used with email messages. Here are some of my remarks on this subject.
Almost a year ago I made some tests with CSS and emails for a personal project involving the creation of HTML templates to be used with email messages. Here are some of my remarks on this subject. Basically, I'm a person whose childhood dream was doing a job where you can help other people. On August 12, 2006 I wrote down on a piece of paper the following quotation from Matthew 25, 35-41:
Basically, I'm a person whose childhood dream was doing a job where you can help other people. On August 12, 2006 I wrote down on a piece of paper the following quotation from Matthew 25, 35-41: Just a couple of minutes ago I've updated my profile on Amazon by providing an alternate email address. The main problem encountered during this procedure was recognizing the correct character sequence in the CAPTCHA image. I had to try several times before typing the correct sequence. So my point is: if a sighted user has encountered so much problems with CAPTCHA images, what will happen to a visually impaired person who tries to fill in the form?
Just a couple of minutes ago I've updated my profile on Amazon by providing an alternate email address. The main problem encountered during this procedure was recognizing the correct character sequence in the CAPTCHA image. I had to try several times before typing the correct sequence. So my point is: if a sighted user has encountered so much problems with CAPTCHA images, what will happen to a visually impaired person who tries to fill in the form? I've just finished to upload a series of old notes on CSS development which include a demo showing how to build an
I've just finished to upload a series of old notes on CSS development which include a demo showing how to build an 


 A year ago I took a seminar in Milan where I spoke on the future possibilities of XML when applied to blogs (you can see the slides
A year ago I took a seminar in Milan where I spoke on the future possibilities of XML when applied to blogs (you can see the slides  The CSS
The CSS